0X00 在Mysql中的索引分类
主键索引
- 主键索引(Primary Key)
- 一张表中只能有一个主键索引
- 一般情况下不需要人工去设置主键索引,因为默认主键有索引
- 主键索引也是唯一的,不允许重复的索引
常规索引
- 常规索引(普通索引,index或key)
- 一张表中可以有多个常规索引
- 常规索引可以用于重复字段,例如年级表中的班级字段
唯一索引
- 唯一索引(Unique Key)
- 一张表中也可以有多个唯一索引,但是唯一索引的字段不能包含重复值,例如年级表中的班级字段在表中肯定会重复出现,索引班级字段不能当做唯一索引
全文索引
- 全文索引(Full Text)
- 表示 全文搜索的索引,FULLTEXT用于搜索很长一篇文章的时候,效果最好
- 用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以
复合索引(联合索引,组合索引)
复合索引,这个知识比较多
- 两个或更多个列上的索引被称作复合索引,如
(index_A,index_B,index_C) - 复合索引在数据库操作期间所需的开销更小,可以代替多个单一索引;
- 同时有两个概念叫做
窄索引和宽索引,窄索引是指索引列为1-2列的索引,宽索引也就是索引列超过2的索引; - 设计索引的一个重要原则就是能用
窄索引不用宽索引,因为窄索引往往比组合索引更有效; 组合索引遵循
最左原则,当建立索引(index_A,index_B,index_C)时,有效索引为(index_A),(index_A,index_B),(index_A,index_C),(index_A,index_B,index_C),无效索引为(index_B),(index_C),(index_B,index_C),下面有实际例子单独使用字段
index_A,可以看到type为ref使用了索引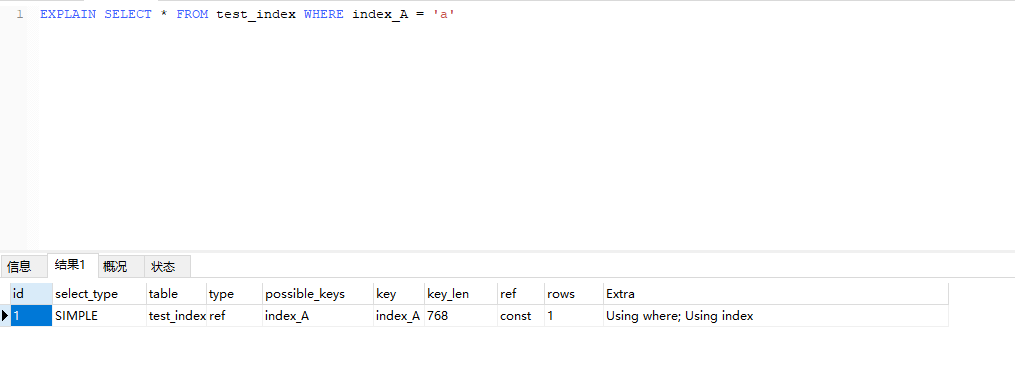
单独使用字段index_B,可以看到type为index,之比ALL好一点,但是还是扫描的全表,效率不行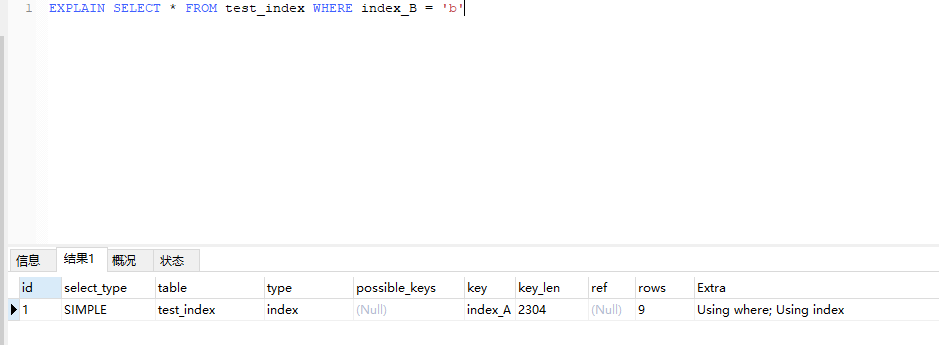
单独使用字段index_C,可以看到type为index,之比ALL好一点,但是还是扫描的全表,效率不行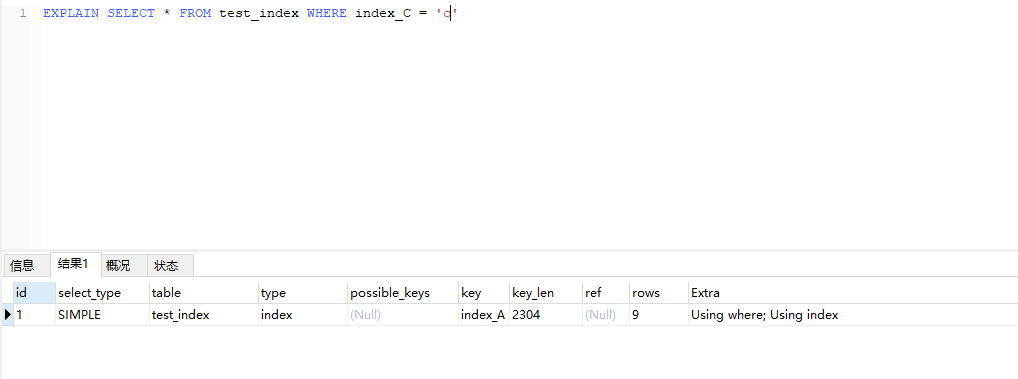
使用组合字段,(index_A,index_B),可以看到type为ref使用了索引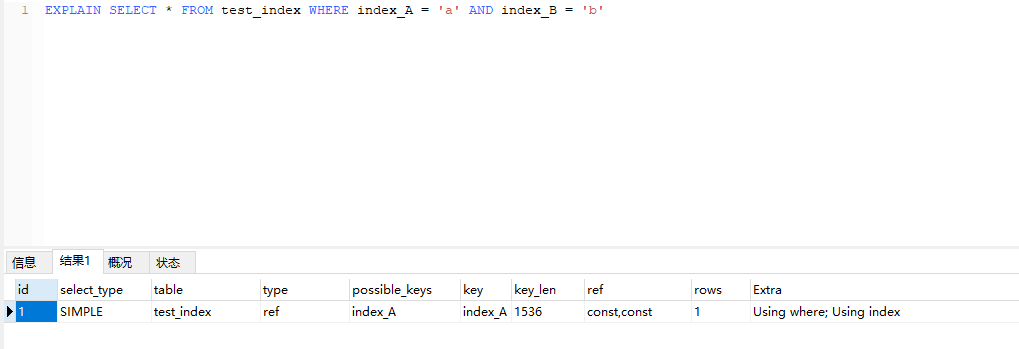
使用组合字段,(index_A,index_C),可以看到type为ref使用了索引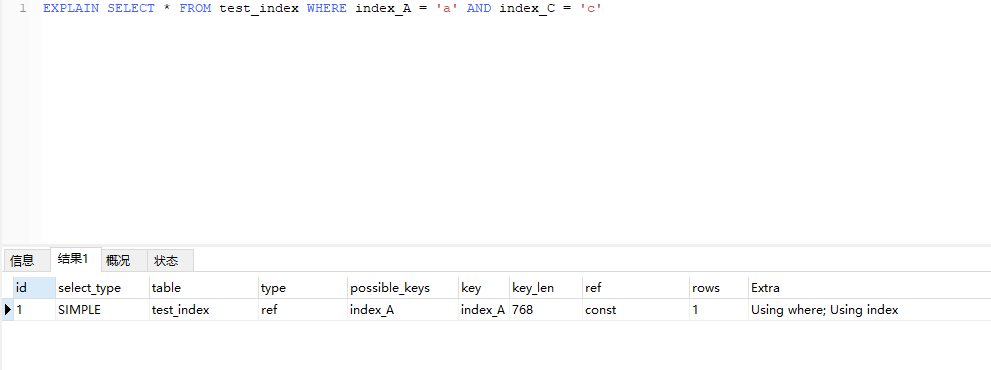
使用组合字段,(index_A,index_B,index_C),可以看到type为ref使用了索引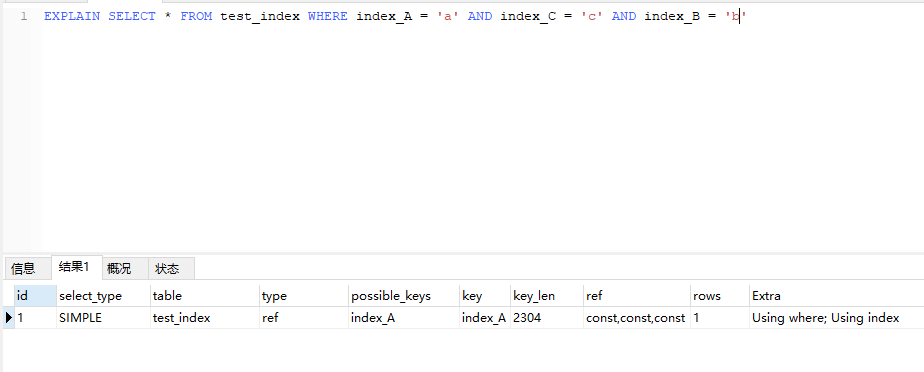
使用组合字段,(index_B,index_C),可以看到type为index,之比ALL好一点,但是还是扫描的全表,效率不行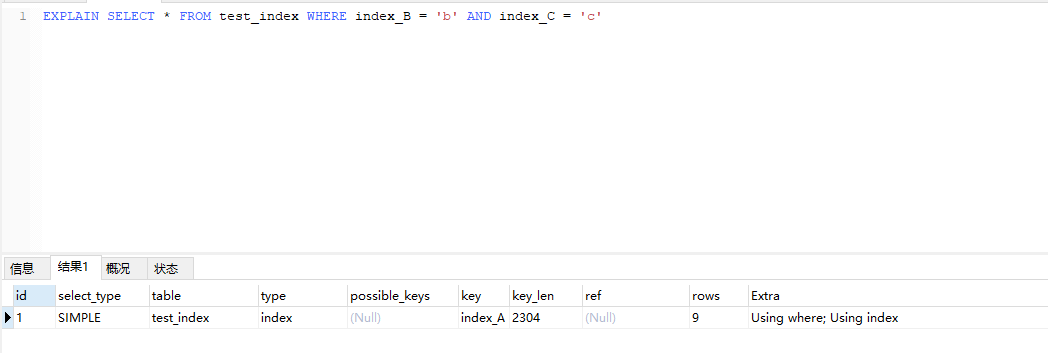
更多资料sql查询用到索引的条件是必须要遵守最左前缀原则,为什么上面有些查询还能用到index类型的索引?
- 上面查询
type字段分别有: index,ref - 解释:
index:这种类型表示是mysql会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个复合索引的一部分,mysql都可能会采用index类型的方式扫描。但是呢,缺点是效率不高,mysql会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。 - 所以当使用字段
index_B时,sql语句为SELECT * FROM test_index WHERE index_B = 'b',索引为(index_A,index_B,index_C),index_B为复合索引的一部分,没有问题,可以进行index类型的索引扫描方式。explain显示结果使用到了索引,是index类型的方式。 - 解释:
ref:这种类型表示mysql会根据特定的算法快速查找到某个符合条件的索引,而不是会对索引中每一个数据都进行一一的扫描判断,也就是所谓你平常理解的使用索引查询会更快的取出数据。而要想实现这种查找,索引却是有要求的,要实现这种能快速查找的算法,索引就要满足特定的数据结构。简单说,也就是索引字段的数据必须是有序的,才能实现这种类型的查找,才能利用到索引。 - 疑问: 索引不都是进行了有序排序吗?
- 解释: 在单个索引下,索引的字段肯定是有序排序的,但是在复合索引下情况就不一样了,复合索引中排序方式也是按照最左原则,比如上面例子的复合索引,排序就是排序最左的
index_A,所以第一个index_A字段是绝对有序的,而第二字段就是无序的了。所以通常情况下,直接使用第二个index_B字段进行条件判断是用不到索引的,当然,可能会出现上面的使用index类型的索引。这就是所谓的mysql为什么要强调最左前缀原则的原因。
- 上面查询
复合索引可以和唯一索引结合在一起使用,也可以和常规索引结合一起使用,比如和唯一索引结合一起使用时,必须保证两个索引的字段在表中都不包含重复值,常规索引则满足常规索引要求即可
这个其实不应该算到索引分类里面的,因为这个相当于结合体
最后引用博主SunnyAmy的图片
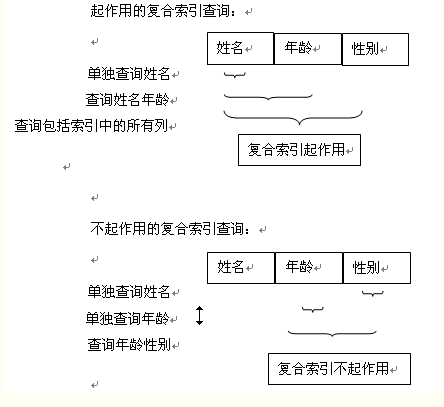
- 两个或更多个列上的索引被称作复合索引,如
外键索引
- 外键索引(外键索引)
- 外键索引我暂时没有接触过这里引用下脚本之家中的介绍吧
- 外键索引(Foreign Key),简称外键,它可以提高查询效率,外键会自动和对应的其他表的主键关联。外键的主要作用是保证记录的一致性和完整性
- 注意:只有InnoDB存储引擎的表才支持外键。外键字段如果没有指定索引名称,会自动生成。如果要删除父表(如分类表)中的记录,必须先删除子表(带外键的表,如文章表)中的相应记录,否则会出错。 创建表的时候,可以给字段设置外键,如 foreign key(cate_id) references cms_cate(id),由于外键的效率并不是很好,因此并不推荐使用外键,但我们要使用外键的思想来保证数据的一致性和完整性。
复合索引的排序选择
- 由于复合索引东西有点多,这里在补充一下
怎样去选择合适的索引列顺序
-
- 最容易引起困惑的就是复合索引中列的顺序。在复合索引中,正确地列顺序依赖于使用该索引的查询,并且同时需要考虑如何更好地满足排序和分组的需要。
索引列的顺序意味着索引首先按照最左列进行排序,其次是第二列,第三列…。所以,索引可以按照升序或者降序进行扫描,以满足精确符合列顺序的order by、group by和distinct等子句的查询需求。
当不需要考虑排序和分组时,将选择性最高的列放到复合索引的最左侧(最前列)通常是很好的。这时,索引的作用只是用于优化where条件的查找。但是,可能我们也需要根据那些运行频率最高的查询来调整索引列的顺序,让这种情况下索引的选择性最高。
- 最容易引起困惑的就是复合索引中列的顺序。在复合索引中,正确地列顺序依赖于使用该索引的查询,并且同时需要考虑如何更好地满足排序和分组的需要。
怎么去选择排序的例子,有条sql为
select * from payment where order_id = 65421 and older_id = 88941;,这种情况下如何去排列复合索引中的older_id和older_id呢?使用
show index from 表名
使用索引基数(cardinality)/数据总量得到的值,越接近1该索引的选择性越高使用
select count(distinct 列名)/count(*) ,count(distinct 列名2)/count(*) from 表名
能看出来order_id的值最大,选择性最高,所以复合索引的排列最好为(order_id,older_id)
- 尽管,关于选择性和全局基数的经验法则值得去研究和分析,但一定别忘了order by、group by 等因素的影响,这些因素可能对查询的性能造成非常大的影响。
0X01 索引的方式方法
B-Tree 索引
- B-Tree 索引
- B-Tree 索引(B树(可以是多叉树)),也是主流的索引方法
- B-Tree 对索引列是顺序存储的,因此很适合查找范围数据。它能够加快访问数据的速度,因为存储引擎不再需要进行全表扫描来获取需要的数据
HASH 哈希索引(key,value)
- 哈希索引
- 哈希索引这种方式对范围查询支持得不是很好
- 哈希索引只有精确匹配索引所有列的查询才有效。在MySQL中,只有Memory引擎显示支持哈希索引。
Mysql索引基数的概念
这里就用工具Navicat做记录吧,方便点,命令行太难看了….
索引基数(cardinality): 索引中不重复的索引值的数量
- 比如,有一张消费记录表,其中的字段消费者ID设置了索引,全表有5条数据,其中消费者ID为2的人记录了两次,数据大致为
(1,2,2,3,4),这时索引的基数就为4
- 比如,有一张消费记录表,其中的字段消费者ID设置了索引,全表有5条数据,其中消费者ID为2的人记录了两次,数据大致为
索引基数相对于数据表行数较高(也就是说,列中包含很多不同的值,重复的值很少)的时候,它的工作效果最好。
- 如果某个数据列用于记录性别(只有”Man”和”Wman”两种值),那么索引的用处就不大。因为选择其中的任意一个索引都可以得到大约一半的数据行,查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。惯用的百分比界线是”30%”。
索引基数的查看
show index from 表名Cardinality列中的数即为索引基数,但是是估计值不是准确值- 为何是估计值而不是准确值?
- 在生产环境中,数据表的更新操作非常频繁,每一次的数据更新操作,都会更新索引文件中的数据,而如果每次都要进行一次该索引中不同索引值的统计会增加系统压力
- 索引基数的初始值
- 新表中添加索引:索引基数为0
- 旧表中添加索引:索引基数为当前表中数据总数
- 索引基数的计算方式
- 采用采样的方法,默认情况下InnoDB会对8个叶子节点的信息进行统计,过程如下:
- 取得B+Tree所有叶子节点的数量,记为A
- 随机取得B+Tree索引的8个叶子节点。统计每个叶子节点的不同记录的条数,即为P1,P2,…,P8
- 根据采样计算出Cardinality的预估值:Cardinality=(P1+P2+…+P8)*A/8
- 采用采样的方法,默认情况下InnoDB会对8个叶子节点的信息进行统计,过程如下:
- 索引基数的更新语句
ANALYZE 表名- 何时自动更新索引基数的值?
- 表中的1/16数据已发生变化:上一次统计Cardinality信息后,表中1/16数据已发生变化,则会触发Cardinality统计
- start_modified_counter>2 000 000 000:为对表中某一行数据频繁进行更新操作,实际数据条数并没有发生变化,则InnoDB会生成start_modified_counter计数器,用来统计操作次数,如果次数大于2 000 000 000,则会触发Cardinality统计
- show index、ANALYZE TABLE、SHOW TABLE STATUS以及访问INFOMATION_SCHEMA架构下的TABLES或STATISTICS会导致Cardinality的统计
- 何时自动更新索引基数的值?
- 为何是估计值而不是准确值?
- 下面看一下
show index from 表名结果中各列的含义引用博主命运的左岸